产品计费
本文档介绍阿里云百炼大模型服务平台的计费模式、类型和整体计费报价单。
为了确保您能清晰地了解产品的计量和计费规则,特别提醒您,所有计量和计费规则均以购买页面上显示的价格为准。对于预付费的计费模式,不同金额对应的折扣政策也会有所不同,具体详情请参考购买页面上的相关信息。
计费项
阿里云百炼大模型服务平台的计费项目涵盖了模型推理、模型训练和模型部署三个环节,分别对应三个使用场景:直接调用预置模型进行推理、对预置模型进行调优,部署预置模型或调优后的模型到独占实例后进行推理。您可先确定是否有模型服务的定制化需求(预置模型或自定义模型),再从模型服务的资源用量、长期化、稳定性、高性能等方面考虑您的应用场景,最后制定适合您的计费方案。以下是三类计费项目的简要介绍:
计费项 | 计费方式 | 适用模型 | 适用场景 |
模型推理费用 | 直接调用预置模型进行推理时,根据实际使用的数量计费(计费单位随模型类型而变化) | 预置模型 | 常见的服务场景,适合临时的模型测试需求,少量的模型推理需求,短期的模型服务需求,灵活的模型选择需求 |
模型训练费用 | 当预置模型不能满足需求,需要对预置模型进行调优时,根据训练过程中实际使用的计算资源和训练时长收取费用 | 自定义模型 | 有模型定制化需求,需要针对实际应用场景微调模型 |
模型部署费用 | 部署预置模型或调优后的模型到独占实例后进行推理时,根据独占实例实际使用的计算资源和运行时长收取费用 | 预置模型、自定义模型 | 有模型定制化需求;有中长期的、弹性的、高负载下稳定的、高并发量的大模型服务需求 |
什么是预置模型和自定义模型?
预置模型是由大型模型服务平台提供的已经训练好的模型,例如通义千问Max、通义千问Turbo等。这些模型经过大规模的训练,拥有丰富的知识和能力,具有广泛的适用性和较高质量的输出,可以直接用于各种自然语言处理任务,如文本生成、情感分析、语言翻译等,对于许多常见的应用场景是一个理想的选择。
自定义模型是基于预置模型进行调优后的定制化模型。用户可以利用自己的数据集对预置模型进行调优,调优后的模型可以学习适应用户数据的特定模式和语境,从而提高在特定任务上的性能和准确性。例如,将预置的计算机视觉模型在医学图像分类任务上进行微调,以提高对病理学图像的准确性和精度。
如何选择这两类模型?
预置模型适用于那些常见的应用场景,而自定义模型则更适用于那些需要个性化定制或者在特定任务上追求更高性能表现的场景。选择哪类模型取决于您的具体需求和目标。
计费详细清单
模型推理计费
模型推理计费适用于直接调用预置模型进行推理,根据模型的资源使用量进行计费。模型推理受到性能限制,与模型服务和模型规格相关。
性能限制包括调用频次(QPM)和Token消耗频次(TPM)两个维度。对于不同模型、特定模型的不同规格,性能限制可能不同。具体性能限制参数请参考百炼产品文档中每个模型文档各自的计量计费文档。
如果您需要更高性能的模型服务,推荐您对预置模型进行模型部署。部署后的预置模型可配置算力单元数量,并支持上线后扩缩容,灵活配置模型服务性能。
模型推理计费有以下配置可供选择:
模型服务:百炼大模型服务平台提供了多种类型的预置模型服务供您选择,涵盖自然语言处理模型、图像识别模型、语音识别模型等大模型。不同模型可能采用不同的计量单元、计费单价和免费额度。
模型规格:同类型的预置模型可能会有不同的规格,它们对性能和资源消耗会有所不同,相应地,输出的内容质量也有差异。例如,除了基础模型,某些模型服务可能还提供长文本模型、高参数量模型和多模态模型等变种模型。这些模型分别针对更长的文本、更高精度的推理计算和多模态输入/输出等需求进行了优化。
计费单价:模型推理的计费单价随着模型服务、模型规格和计费模式而变化,例如,大语言类模型通常根据输入/输出的Token数量进行计费,语音识别类模型采用输入语音文件的时长进行计费。大语言模型通常采用输入(input)和输出(output)分别计费的方式,这是因为模型在推理过程中,输入和输出的资源消耗不同。
输入(input)计费:针对用户向模型提交的请求数据进行计费。这包括了用户提交给模型的文本、图像、音频等原始数据。
输出(output)计费:针对模型返回给用户的输出结果进行计费。这包括了模型生成的文本、图像、音频等处理结果。
计费模式:模型推理的计费模式分为后付费和预付费(适用于通义千问大模型推理节省计划)两种。
后付费:按实际使用量进行计费,在每个计费周期结束后结算费用。适合于使用量不确定或需要灵活调整资源使用的场景。
预付费:提前购买一定量的资源或服务,按照预先支付的费用使用。适合于对使用量有较明确预估的场景,通常会享有一定的折扣优惠。
什么是通义千问大模型推理节省计划?
通义千问大模型推理节省计划是面向通义千问Turbo和通义千问Plus规格推出的预付费推理资源包。本计划适用于所有用户,用户可根据不同的预付费金额享受相应的折扣力度,共提供4个档位的折扣。下单后,节省计划将立即生效,有效期为1年。如有疑问,请您提交工单反馈,会有专员解答您的问题。
预付费金额区间 | 对应折扣 |
100~900元 | 98折 |
1000~4000元 | 95折 |
5000~19000元 | 92折 |
20000~30000元 | 9折 |
Token是怎么计算的?
Token是模型用来表示自然语言文本的基本单位,可以直观地理解为“字”或“词”。具体说明如下:
对于中文文本,1个token通常对应一个汉字或词语。
对于英文文本,1个token通常对应3至4个字母或1个单词。
例如,中文文本“你好,我是通义千问”会被转换成序列['你好', ',', '我是', '通', '义', '千', '问']。
英文文本"Nice to meet you."则会被转换成['Nice', ' to', ' meet', ' you', '.']。
通义千问模型服务根据模型输入和输出的token数量进行计费,其中多轮对话中的history作为输入也会进行计费。
通义千问大语言模型
通义千问是阿里云自主研发的大语言模型,专门用于理解和分析用户输入的自然语言,并在不同领域和任务中为用户提供服务和帮助。通义千问具有多功能性,能够撰写邮件、周报和提纲;创作诗歌、小说和剧本;编写代码;制作表格,甚至进行角色扮演。它可以灵活地响应各种指令,满足不同的需求。
模型服务 | 模型规格 | 输入(input)价格 | 输出(output)价格 | 计费模式 |
通义千问Turbo | qwen-turbo | ¥0.008/1,000 tokens | ¥0.008/1,000 tokens | 后付费 |
¥100、¥1000、¥5000、¥20000 | 预付费 | |||
通义千问Plus | qwen-plus | ¥0.02/1,000 tokens | ¥0.02/1,000 tokens | 后付费 |
¥100、¥1000、¥5000、¥20000 | 预付费 | |||
通义千问Max | qwen-max | ¥0.12/1,000 tokens | ¥0.12/1,000 tokens | 后付费 |
qwen-max-0428 | ||||
qwen-max-0403 | ||||
qwen-max-0107 | ||||
qwen-max-1201 | ||||
qwen-max-longcontext | ||||
通义千问VL
通义千问VL视觉理解大模型,具备通用OCR、视觉推理、中文文本理解基础能力,还能处理各种分辨率和规格的图像,甚至能“看图做题”。
模型服务 | 模型规格 | 价格 | 计费模式 |
通义千问VL | qwen-vl-plus | ¥0.008/1,000 tokens | 后付费 |
qwen-vl-max | ¥0.02元/1,000 tokens | 后付费 |
通义千问开源模型
通义千问开源模型由阿里云研发,提供多个规模的开源版本,包括18亿、70亿、140亿和720亿参数的模型。这些模型基于Transformer结构,并在超大规模的预训练数据上进行训练。预训练数据类型多样且覆盖广泛,包括大量网络文本、专业书籍和代码等。
模型服务 | 模型规格 | 输入(input)价格 | 输出(output)价格 | 计费模式 |
通义千问110B | qwen1.5-110b-chat | 限时免费中 | 限时免费中 | 后付费 |
通义千问72B | qwen-72b-chat | 0.02元/1,000 tokens | 0.02元/1,000 tokens | 后付费 |
qwen1.5-72b-chat | ||||
通义千问32B | qwen1.5-32b-chat | 限时免费中 | 限时免费中 | 后付费 |
通义千问14B | qwen-14b-chat | 0.008元/1,000 tokens | 0.008元/1,000 tokens | 后付费 |
qwen1.5-14b-chat | ||||
通义千问7B | qwen-7b-chat | 0.006元/1,000 tokens | 0.006元/1,000 tokens | 后付费 |
qwen1.5-7b-chat | ||||
通义千问1.8B | qwen-1.8b-chat | 限时免费中 | 限时免费中 | 后付费 |
通义千问0.5B | qwen1.5-0.5b-chat | 限时免费中 | 限时免费中 | 后付费 |
通义万相(文生图)
通义万相是基于阿里云自研的Composer组合生成框架的AI绘画创作大模型。它能够根据用户输入的文字内容生成符合语义描述的不同风格的图像,结果自然且细节丰富。通义万相还提供了图像背景生成和人像风格重绘模型,以满足多样化的绘画需求。
模型服务 | 模型规格 | 价格 | 计费模式 |
通义万相-文本生成图像 | wanx-v1 | 0.16元/张 | 后付费 |
通义万相-人像风格重绘 | wanx-style-repaint-v1 | 0.12元/张 | |
通义万相-图像背景生成 | wanx-background-generation-v2 | 0.08元/张 | |
通义万相-涂鸦作画 | wanx-sketch-to-image-lite | 0.06元/张 |
Sambert语音合成模型
Sambert语音合成模型提供实时语音合成API,可将文字内容转化为音频。除语音数据外,还可选择开启字级别和音素级别时间戳,用于生成字幕或驱动数字人的口型。Sambert语音合成模型适用于客服、直播、方言、童声等场景。
模型服务 | 模型规格 | 价格 | 计费模式 |
Sambert系列模型 | 1元/万字 | 后付费 |
Paraformer语音识别模型
Paraformer语音识别API是基于通义实验室新一代非自回归端到端模型开发的,提供基于实时音频流的语音识别功能,并支持对各类音视频文件进行语音识别,可应用于实时语音识别、音视频文件识别、电话客服录音识别等场景。
模型服务 | 模型规格 | 价格 | 计费模式 |
录音文件识别 | paraformer-v1 | 0.00008元/秒 | 后付费 |
paraformer-8k-v1 | |||
paraformer-mtl-v1 | |||
实时语音识别 | paraformer-realtime-v1 | 0.00024元/秒 | 后付费 |
paraformer-realtime-8k-v1 |
通用文本向量模型
通用文本向量是通义实验室基于大型语言模型(LLM)底座开发的多语言文本统一向量模型。该模型旨在面向全球多个主流语种提供高水准的向量服务,帮助开发者将文本数据快速转换为高质量的向量数据。
模型服务 | 模型规格 | 价格 | 计费模式 |
通用文本向量 | text-embedding-v1 | 0.0007元/1000 tokens | 后付费 |
text-embedding-async-v1 | |||
text-embedding-v2 | |||
text-embedding-async-v2 |
OpenNLU文本理解模型
OpenNLU(全称 Open Domain Natural Language Understanding)是一个开箱即用的文本理解大模型,适用于中文和英文在零样本条件下进行文本理解任务,如信息抽取和文本分类等。
模型服务 | 模型规格 | 价格 | 计费模式 |
OpenNLU开放域文本理解模型 | opennlu-v1 | 0.00465元/1000 tokens | 后付费 |
多模态文生图
多模态文生图(Text-to-Image Generation)是一种利用文本描述生成图像的技术。该技术结合自然语言处理和计算机视觉,通过理解和分析文本输入,生成与之匹配的图像。这种技术在多个领域具有广泛的应用前景,包括艺术创作、广告设计、教育、娱乐等。
模型服务 | 模型规格 | 价格 | 计费模式 |
StableDiffusion文生图模型 | stable-diffusion-xl | 限时免费中 | 后付费 |
stable-diffusion-v1.5 | |||
Wordart文字纹理生成API | wordart-texture | 0.08元/张 | 后付费 |
Wordart文字变形API | wordart-semantic | 0.24元/张 | |
FaceChain人物图像检测 | facechain-facedetect | 限时免费中 | 后付费 |
FaceChain人物形象训练 | facechain-finetune | 2.5元/次 | 后付费 |
FaceChain人物写真生成 | facechain-generation | 0.18元/张 | 后付费 |
多模态向量表征模型
ONE-PEACE是一个图文音三模态通用表征模型,在语义分割、音文检索、音频分类和视觉定位几个任务都达到了新SOTA表现,在视频分类、图像分类、图文检索以及多模态经典benchmark也都取得了比较领先的结果。
模型服务 | 模型规格 | 价格 | 计费模式 |
ONE-PEACE多模态向量表征 | multimodal-embedding-one-peace-v1 | 限时免费中 | 后付费 |
三方开源大语言模型
如需进一步了解下列三方开源大语言模型的功能简介,请参考三方开源大语言模型。
模型服务 | 模型规格 | 输入(input)价格 | 输出(output)价格 | 计费模式 |
Llama3 大语言模型 | llama3-8b-instruct | 限时免费中 | 限时免费中 | 后付费 |
llama3-70b-instruct | 后付费 | |||
Llama2 大语言模型 | llama2-7b-chat-v2 | 后付费 | ||
llama2-13b-chat-v2 | ||||
百川模型2-13B对话版 | baichuan2-13b-chat-v1 | 0.008元/1,000 tokens | 0.008元/1,000 tokens | 后付费 |
百川模型2-7B对话版 | baichuan2-7b-chat-v1 | 0.006元/1,000 tokens | 0.006元/1,000 tokens | |
百川模型1 | baichuan-7b-v1 | 限时免费中 | 限时免费中 | 后付费 |
ChatGLM2开源双语对话语言模型 | chatglm-6b-v2 | 0.006元/1,000 tokens | 0.006元/1,000 tokens | 后付费 |
ChatGLM3开源双语对话语言模型 | chatglm3-6b | 限时免费中 | 限时免费中 | 后付费 |
姜子牙通用大模型V1 | ziya-llama-13b-v1 | 限时免费中 | 限时免费中 | 后付费 |
Dolly开源大语言模型 | dolly-12b-v2 | 限时免费中 | 限时免费中 | 后付费 |
BELLE开源中文对话大模型 | belle-llama-13b-2m-v1 | 限时免费中 | 限时免费中 | 后付费 |
MOSS开源对话语言模型 | moss-moon-003-sft | 限时免费中 | 限时免费中 | 后付费 |
moss-moon-003-base | 限时免费中 | 限时免费中 | 后付费 | |
元语功能型对话大模型V2 | chatyuan-large-v2 | 限时免费中 | 限时免费中 | 后付费 |
BiLLa开源推理能力增强模型 | billa-7b-sft-v1 | 限时免费中 | 限时免费中 | 后付费 |
模型训练计费
模型训练计费是对预置模型进行调优时,根据训练过程中实际使用的计算资源和训练时长收取费用。具体费用可以通过以下公式计算:
模型训练费用=训练集Tokens总数×循环次数×训练单价
训练集Tokens总数是指在训练过程中使用的所有tokens的总数量。训练集Tokens总数决定了训练数据的规模,训练数据越大,训练效果可能越好,但同时也会消耗更多的资源。
循环次数(Epoch)是指整个训练集在训练过程中被完整迭代的次数。每次循环(Epoch)中,模型会通过整个训练集进行学习和调整。通常,更多的循环次数会提高模型的性能,但也会增加训练时间和成本。
训练单价是指每1,000个token在一次循环中的训练费用。训练单价会根据所使用的模型服务和模型规格而有所不同。
模型训练过程中因为等待时间太久,主动取消训练会产生计费么?
会的,如果您主动取消训练,之前已产生的费用仍会被计费;但如果训练是因失败终止的,则不会产生费用。
模型服务 | 模型规格 | 训练方式 | 价格 | 计费模式 |
通义千问Turbo | qwen-turbo | SFT训练 | ¥0.03/1,000 tokens | 后付费 |
通义千问Plus | qwen-plus | SFT训练 | ¥0.15/1,000 tokens | 后付费 |
通义千问开源系列 | qwen-7b-chat | SFT训练 | ¥0.006/1,000 tokens | 后付费 |
qwen-14b-chat | SFT训练 | ¥0.03/1,000 tokens | 后付费 | |
qwen-72b-chat | SFT训练 | ¥0.15/1,000 tokens | 后付费 | |
qwen1.5-7b-chat | SFT训练 | ¥0.006/1,000 tokens | 后付费 | |
qwen1.5-14b-chat | SFT训练 | ¥0.03/1,000 tokens | 后付费 | |
qwen1.5-72b-chat | SFT训练 | ¥0.15/1,000 tokens | 后付费 |
模型部署计费
模型部署计费是部署预置模型或调优后的模型到独占实例后进行推理时,根据独占实例实际使用的算力单元和运行时长收取费用。部署后的模型可以灵活配置模型服务性能,满足您弹性的、高性能的、稳定的、长期的模型服务需求。
模型部署计费支持包月资源和按量付费两种类型,您可以根据需求选择适合的模型服务、模型规格和计费模式进行部署。
包月资源:预付费模式,您需要提前购买资源包,支付后即锁定资源,按月进行结算。平台将使用您已购买的资源包进行模型部署。此模式适合长期服务的稳定模型。
按量付费:后付费模式,按量付费按实际使用时长计费,无需提前购买资源。您可以根据需求灵活使用,模型上线即开始计费,模型下线即停止计费。此外还支持弹性扩缩容,灵活调整独占实例资源量。此模式适用于即购即用的短期服务模型。您可查看算力单元,确定您要配置的独占实例数量。
模型服务 | 模型规格 | 价格 | 计费模式 |
大模型独占实例 | qwen-turbo | ¥20,000.00/月 | 预付费 |
¥40/实例/小时 | 后付费 | ||
qwen-plus | ¥80,000.00/月 | 预付费 | |
¥160/实例/小时 | 后付费 | ||
qwen-max | ¥160,000.00/月 | 预付费 | |
¥320/实例/小时 | 后付费 |
独占实例费用是如何计算的?
模型部署计费按独占实例数进行计费。实例是由算力单元组成,不同模型的实例对应的算力单元不同。以下是关于部署费用的详细说明:
部署费用计算:
部署费用 = 算力单元 × 算力单元单价
算力单元单价为20元/小时
费用规则:
部署失败不收取费用。
按量付费模式下,部署成功后开始计费。
包月资源模式下,需要提前购买资源实例,部署成功后不再额外计费。
举例:
qwen-turbo:1个实例 = 2个算力单元 = 20元/小时 × 2 = 40元/小时
qwen-plus:1个实例 = 8个算力单元 = 20元/小时 × 8 = 160元/小时
qwen-max:1个实例 = 16个算力单元 = 20元/小时 × 16 = 320元/小时
qwen-max-1201:1个实例 = 16个算力单元 = 20元/小时 × 16 = 320元/小时
不同模型对应的算力单元数不同,详细内容请在模型部署控制台页面查看。
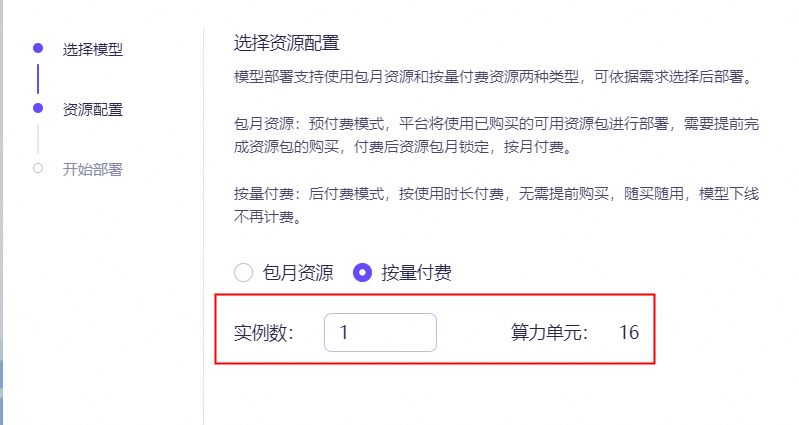
计费示例:小A在阿里云百炼平台部署了1个小时的qwen-plus模型,账单显示了一笔320元的费用。请问小A应该怎么理解费用明细?
解答:
首先,qwen-plus一个实例部署的费用为160元/小时,正常情况下应该收费160元,但实际收取了320元。
其次,已知1个算力单元的费用为20元/小时,并且qwen-plus的实例部署费用为160元/小时,则qwen-plus的1个实例需要8个算力单元(160元 ÷ 20元/小时 = 8个算力单元)。
最后,实际消费320元,那么320元 ÷ 20元/小时 = 16个算力单元。由此推测,小A在部署模型时可能选择了2个实例(每个实例8个算力单元),所以导致最终收费金额为320元。
因此,小A的账单显示的320元是因为部署了2个qwen-plus实例,每个实例的费用是160元/小时。
常见问题
当前如何开通模型推理服务?
发起模型部署(大模型独占实例)时,一般会有几种状态,分别代表什么意思?
状态
操作
计费情况
部署中
查看
此状态不计费
运行中
查看、扩缩容、下线
此状态持续计费,点击下线后部署任务消失,停止计费
欠费停服
查看、删除
此状态不计费,欠费状态不会持续计费,但充值后,模型将恢复服务,自动恢复后将开始计费,点击删除后部署任务消失,不再计费
欠费恢复中
查看
此状态不计费,表示账户已充值,系统自动恢复服务中,服务恢复后,状态变换为运行中将恢复计费
部署失败
查看、删除、重新部署
此状态不计费,重新部署成功后变为运行中状态将进行计费,点击删除后部署任务消失,不再计费
部署环节过程中,如果您不想继续部署服务,是否可以暂停?是否有页面引导?
当状态为“部署中”时,可以点击下线/删除按钮来暂停部署服务。下线即相当于删除部署任务。页面上会有相应的引导和操作按钮,帮助您进行这些操作。
模型评测是否会产生计费?
模型的维度管理不收费。模型评测是否产生费用取决于评测方式:
通过独立部署完成的模型评测:不收费。
使用预置模型进行评测:会产生计费。
怎么增加并发量?以及大概怎么收费?
不同模式有不同说明:
按tokens调用模式(即模型推理计费模式,仅适用于预置模型):目前暂不支持增加并发量。如果业务实际需要增加并发量,请先联系对接的商务同学反馈给产品团队。
按独占实例部署模式:如果客户希望独立部署模型调用,每实例当前的并发量约为1.5。客户可以按照并发量进行计算,并购买对应数量的独占实例。目前独占实例只支持训练之后的模型以及基础版模型。例如,客户需要3并发,则购买2个独占实例即可。
如果有抵扣券或者优惠券,产生的费用如何扣费?
阿里云扣费顺序请前往阿里云后付费账单扣款顺序查询。
怎么查看后付费的账单?
有关账单详情请前往阿里云用户中心查询。
怎么查看已开通的节省计划?
点击阿里云账号的用户中心-节省计划可以查看开通及使用情况。
- 本页导读 (1)